Returning to Regression
Returning to regression
- Moving from description to inference
- Review of regression conditions
- Sampling distribution of models
- Inference for regression
Moving from description to inference
Returning to regression
How would you interpret all parts of this model except the value, and ?
Model
- The equation of the least squares line
- Slope of -15.35 indicates that the miles per gallon of cars is on average 15.35 less for each additional ton the car weighs.
- How useful is the model?
- Slope and intercept are descriptions of data - want to know how certain we are of this slope estimate
- Want to understand what it can tell us beyond the 400 cars in the study
- Construct CI, test hypotheses about slope, intercept
Sample vs. model regression
- Sample:
- This gives a prediction for based on the sample.
- Model:
- = y-intercept for the model
- = slope for the model
- The model assumes that for every value of , the mean of the ’s lies on the line.
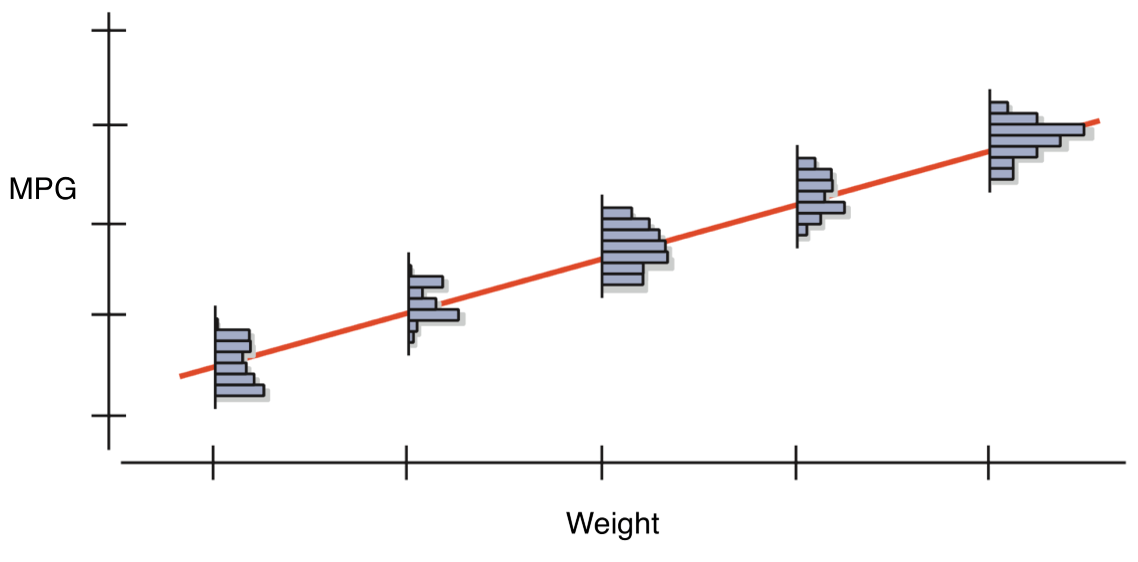
Just as with a mean, if we sample many times from a population, we will, by chance, get variation in our estimate of the slope of the relationship between the two variables.
We can then make a histogram of each of these slope estimates.
In expectation, what shape should we expect the distribution of slope estimates to conform to? Why?
Errors
- The model predicts the mean of for each , but misses the actual individual values of
- The error, e, is the amount the line misses the value of .
- This new equation gives the exact value of each of the ’s.
Review of regression conditions
Straight enough condition
- Straight enough condition
- Does the scatterplot look relatively straight?
- Don’t draw the line. It can fool you.
- Look at scatterplot of the residuals.
- Should have horizontal direction
- Should not have a pattern
- If straight enough, check the other assumptions.
- If not straight, stop or re-express.
- Does the scatterplot look relatively straight?
Independence assumption
- Errors (’s) must be independent of each other.
- Check residuals plot.
- Should not have clumps, trends, or a pattern.
- Should look very random.
- To make inferences about the population, the sample must be representative.
- For , plot residuals vs. residuals one step later.
- Should look very random
- Check residuals plot.
We can partially check the independence assumption by viewing the residuals.
Equal variance assumption
- Variability of same for all
- Does the plot thicken? condition: Spread along the line should be nearly constant.
- “Fan shape” is bad.
- Standard deviation of residuals, , will be used for CI and hypothesis tests.
- This requires same variance for each .
- Does the plot thicken? condition: Spread along the line should be nearly constant.
The equal variance assumption can be analyzed by also viewing the residual plot.
Normal population assumption
- As with the and test, we are relying on the Central Limit Theorem that our sampling distribution of our statistic being normally distributed
- Statistic in this case is not mean but regression coefficient
- To meet this condition, the errors for each fixed must follow the Normal model.
- Good enough to use the Nearly Normal Condition and the Outlier condition for the predictors.
- Look at the histograms.
- With large sample sizes, the Nearly Normal Condition is usually satisfied.
The normal population assumption can be partially checked by viewing a histogram of the residuals.
Do these plots indicate that the conditions for regression are satisfied?
Which comes first, the conditions or the residuals?
- Check Straight Enough Condition with scatterplot.
- Fit regression, find predicted values and residuals.
- Make scatterplot of residuals and check for thickening, bends, and outliers.
- For data measured over time, use residuals plot to check for independence.
- Check the Nearly Normal Condition with a histogram and Normal plot of residuals.
- If no violations, proceed with inference.
- Note: Stop if at any point there is a violation.
Sampling distribution of models
Sample to sample variation of the slope and intercept
- Null hypothesis (usually) - regression slope = 0
- values in the table come from tests of this hypothesis for each coefficient.
- To calculate value, we need to describe our sampling distribution.
- The mean of the sampling distribution of the regression slope will be 0, from the null hypothesis.
- We assume shape of the sampling distribution will be normal (from the Central Limit Theorem)
- Standard errors (or our estimate of the standard deviation of the sampling distribution) must come from the data.
- Each sample of 400 cars will produce its own line with slightly different ’s and ’s.
Spread around the line
- Less scatter along the line slope more consistent
- Residual standard deviation, , measures this scatter.
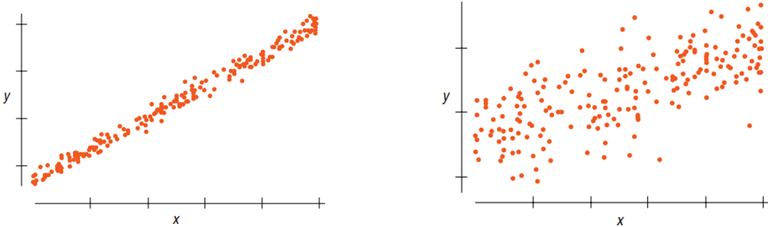
- Less scatter around the line, smaller the residual standard deviation and stronger the relationship between and
- Some assess strength of regression by looking at
- It has the same units as
- Tells how close data are to the our model.
- is proportion of the variation of accounted for by
- Larger (SD in ) more stable regression
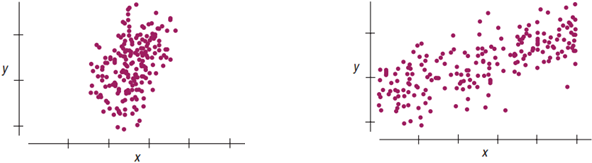
Sample size
- Larger sample size more stable regression
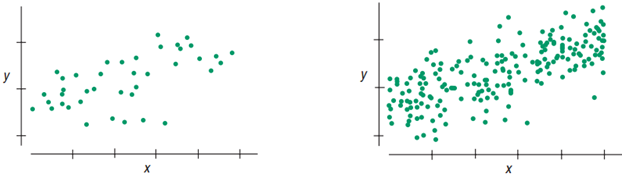
Standard error for the slope
- Three aspects of the scatterplot, then, affect the standard error of the regression slope:
- Spread around the model:
- Variation among the values.
- Sample size:
- These are in fact the only things that affect the standard error of the slope.
Standard error formally
- The standard error for the slope parameter is estimated by:
- where
- We can then calculate how many units our slope estimate is from the null hypothesis by:
- The follows Student’s model with
- Don’t need to remember the SE formula, just note that the process is exactly the same as for the mean
- Find the number of units the slope is away from the mean
- Use that score to find a value of how likely it would be to observe a difference in slopes that larger or larger from the null just by chance
Inference for regression
Example - wages
- It has long been known women earn less than men, and this fact is often taken as evidence of discrimination
- How to test with statistics though?
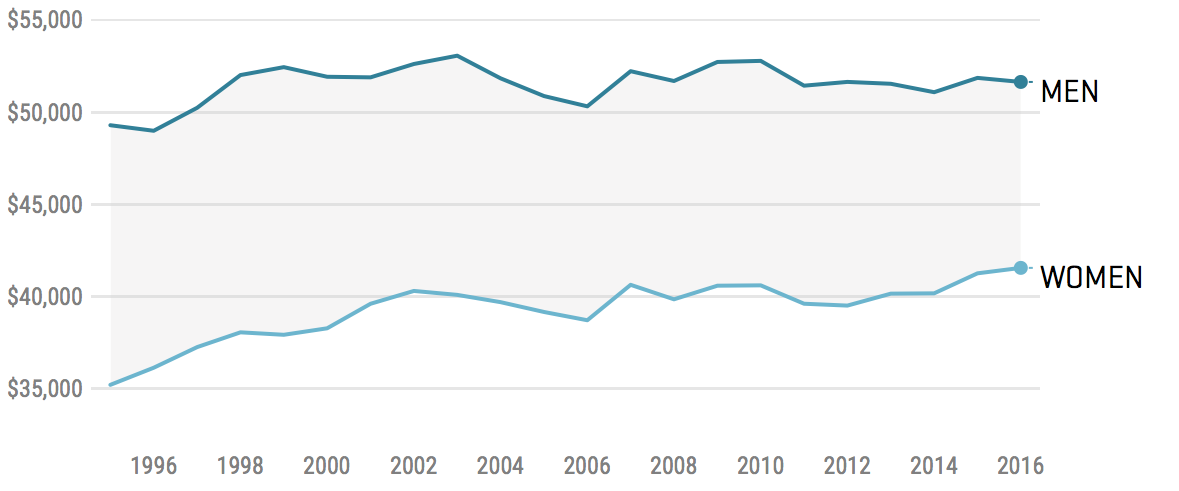
What about a test?
- Slam dunk case right??
What are some reasons why this test might be misleading?
Other factors
- Women dropping out of the labor force
- Impact of high earning men influencing the calculation (outliers)
- Women’s career choice
- Differences in educational attainment
- Other factors?
1. Check straight enough condition
Two-way scatterplots
Histogram of wage
Histogram of log(wage)
Do these plots suggest the straight enough condition has been met?
2. Fit the regression
Interpret this regression table.
3. Check the residuals
4. Check the Nearly Normal condition of the residuals
Do the residual plots suggest the conditions of the residuals have been met?
5. Proceed with inference
How should we understand the coefficient of from the regression compared to the simple difference of means between male and female?
Collinearity
- Variables are said to be collinear when their correlation is very high
- Ex: HDI score and GDP/capita
- What the regression model is trying to do is apportion the amount of responsibility of each predictor independent of the other predictors
- i.e. What is the impact of female INDEPENDENT of all other predictors?
Collinearity
- When predictor is collinear
- Coefficient surprising: unanticipated sign or unexpectedly large or small value
- SE of coefficient can be inflated, leading to smaller statistic, larger value
- What to do?
- Remove some of the predictors
- Simplifies model, improves statistic of slope (usually)
- Keep those most reliably measured, least expensive to find, or ones that are politically important
- Remove some of the predictors