Lecture 3.4 - Hypothesis testing wisdom
Hypothesis testing wisdom
- vs.
- Choosing the right hypothesis test
- Interpreting values
- Alpha levels and critical values
- Practical vs. statistical significance
- Errors
vs.
vs. test
| Know | Variable is continuous | Variable is proportion |
|---|---|---|
| Yes | ||
| No | Depends on CI vs. hypothesis test |
When to use true population parameter
| Know | Hypothesis test | Confidence interval |
|---|---|---|
| Yes | from null | If sample is representative, |
| No | from null | Use |
Choosing the right hypothesis test
Alternatives - two sided
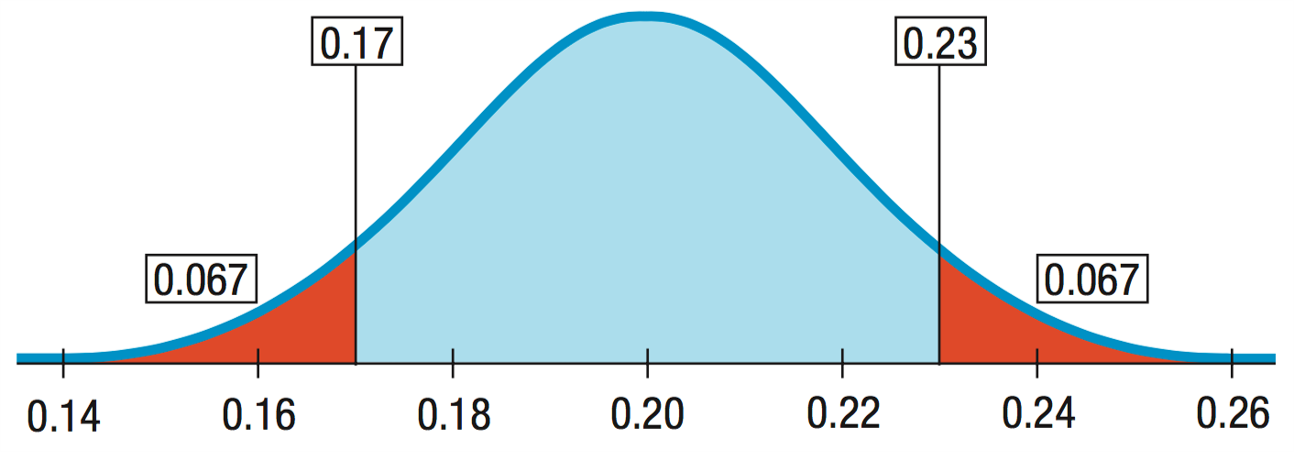
Alternatives - two sided
Old rate is 20%.
Error could be in either direction
Alternatives - one sided
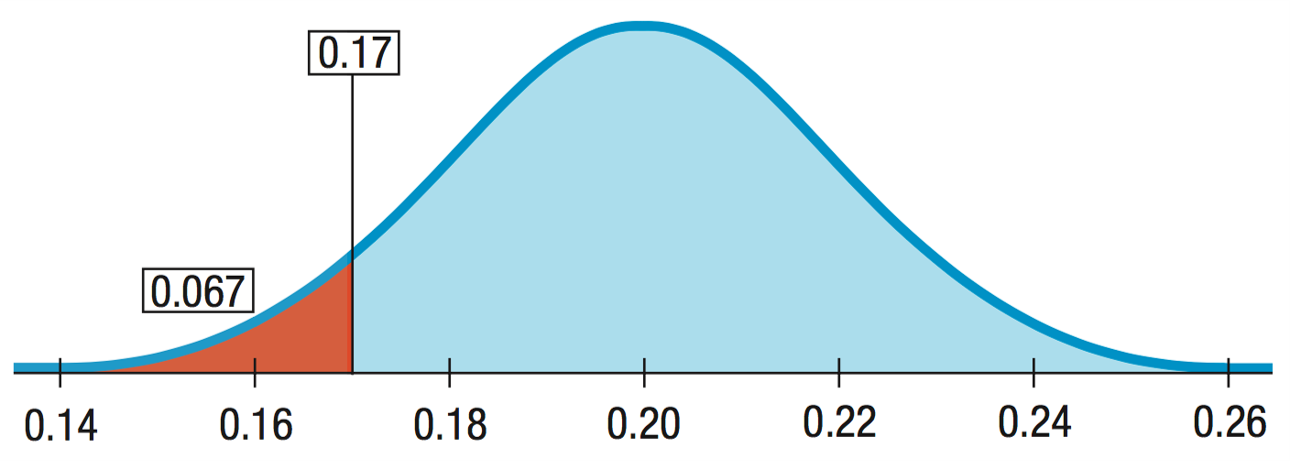
Alternatives - one sided
Interested only in a decrease in the rate:
One-sided alternative
Alternatives - one sided
- One-sided: value is probability only in the direction of the alternative away from the null hypothesis value.
- One-sided value is half the two-sided value.
- One-sided test will reject the null hypothesis more often.
- Great that it rejects the null hypothesis more often when it is false but not so much when it rejects it more often when it is true!
- Two-sided rejects less often
- So use two-sided unless you can justify using one-sided
- Advantage of two-sided test is results matched to CI.
Confidence interval test
- Two ways to test a hypothesis
- Way 1: Construct CI, assume null is true, evaluate: is your value a likely mean of null quantity
- Select
- Select critical value of
- or
- CI:
- Is your observed value within the CI?
- If yes, value consistent with null
- If no, reject null
Example: vineyards

Example: vineyards
Example: vineyard size
- Select null:
- Select critical value of
- or
- CI:
- Is the null value within the CI?
- Null: , yes within CI
- Cannot reject null
value test
- Way 2: Estimate the specific likelihood of observing your mean if we expect the null hypothesis to be true
- Select null
- Set critical value derived from
- Look up value of that score given your that is how unlikely your sample mean is assuming null is true
- Compare to cutoff value
- If smaller than the cutoff value, your sample mean is too unlikely reject null
- If larger than cutoff value, your sample mean is within the likely values of the null; do not reject null
Example: vineyard size
- Select null:
- Set critical value derived from
- Look up p value of that t score given your df that is how unlikely your sample is assuming null is true
- Compare to cutoff value: 0.025 < 0.381 < 0.975 cannot reject null
Interpretation
Either provides you with same information; how likely is your sample to be the same as
CI specifies the range of likely values
value specifies the specific likelihood
Practically, value often more important
- You can set a cutoff value but reader also needs to know how unlikely your result is
- Maybe they think another cutoff value more important
Interpreting values
value is a conditional probability
- The value is the probability of getting results as unusual as observed given that is true.
- The value never gives a probability that is true.
- does not mean a 3% chance of being correct.
- It just says that if is correct, then there would be a 3% chance of observing a statistic value more unlike what was observed.
Small values
- A smaller value provides stronger evidence against .
- This does not mean that is less true.
- The person is not more guilty, you just are more convinced of the guilt.
- There is no hard and fast rule on how small is small enough.
- How believable is ?
- Do you trust your data?
How guilty is the suspect?
- A bank robbery trial:
- Both robber and defendant are male and same height and weight.
- value getting smaller
- Robber wore blue jacket like one found in trash near defendant’s house.
- value still smaller
- Both robber and defendant are male and same height and weight.
- Evidence rolls in, value small enough, “beyond reasonable doubt”
- However, does not make him any guiltier
- Just more confident that made right decision
Alpha levels and critical values
How to define “rare enough”
Need to make a decision whether value is low enough to reject .
Set a threshold value, called the alpha level ().
:
- Reject .
- The results are statistically significant (may not be practically significant!!)
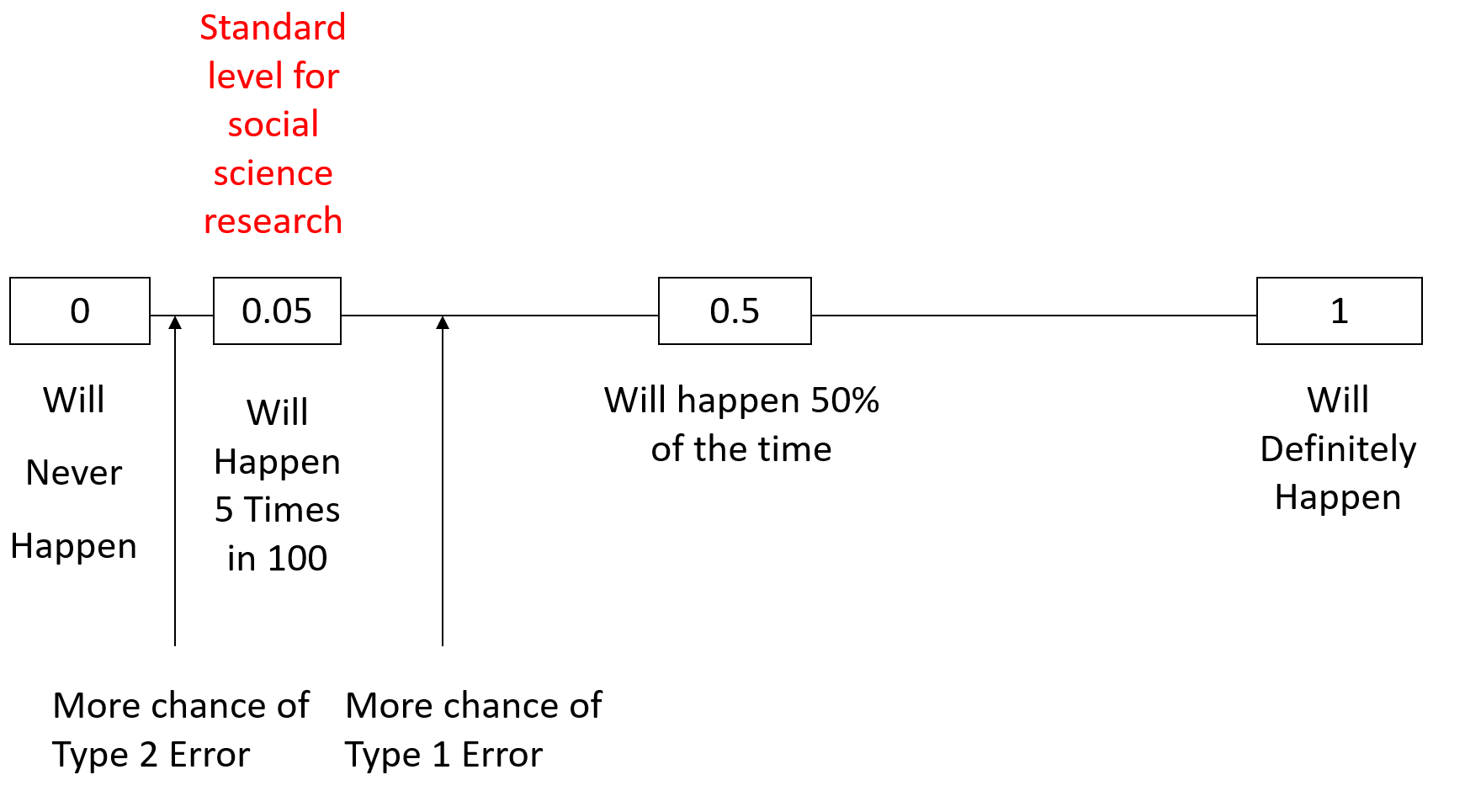
Common levels are 0.10, 0.05, 0.01, and 0.001.
0.05 is often used.
Select level before collecting data.
Significance level
is also called the significance level.
When reject null hypothesis, test is “significant at that level”
Reject the null hypothesis “at the 5% significance level”
Automatic nature may be uncomfortable
value slightly above alpha level, not allowed to reject the null
value slightly below the alpha level leads to rejection
If this bothers you, you’re in good company.
Report the value.
Critical value
- For every null model, an level specifies an area under the curve
- The cutpoint for that area is called a critical value.
- Normal model: critical value is
- model: critical value is
- We have used critical values of 1, 2, and 3 when we talked about the 68-95-99.7 Rule.
- Likely to choose levels like 0.1, 0.05, 0.01, or 0.001, with corresponding critical values of 1.645, 1.96, 2.576, and 3.29.
- For a one-sided alternative, divide the level in half.
Practical vs statistical significance
Practical vs statistical significance
- Statistical significance
- If you don’t know the level, then you don’t know what “significant” means.
- Sometimes used to suggest meaningful or important.
- Test with small value may be surprising
- But says nothing about the size of the effect
- That’s what determines whether the effect makes a difference.
- Don’t be lulled into thinking a statistical significance carries with it any sense of practical importance.
Effect size
- Practical significance
- Reject null hypothesis – care about the actual change or difference in the data
- Effect size – difference between data value and null value
- Large samples – even a small, unimportant effect size can be statistically significant
- Sample not large enough – even a large financially or scientifically important effect may not be statistically significant
- Report CI, value – indicates range of plausible values
- CI centered on the observed effect, puts bounds on how big or small the effect size may actually be
If we were making a new drug, what would a reasonable effect size be? What are the factors we should consider? How about when testing the new drug’s safety?
Hypothesis testing errors
Type I and Type II errors
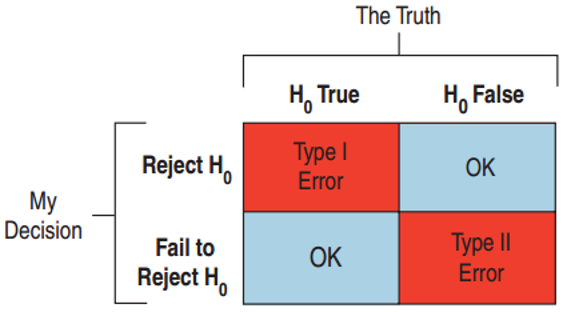
Type I and Type II errors
- Type I Error
- Reject when is true.
- Type II Error
- Fail to reject when is false.
- Medicine: such as an AIDS test
- Type I Error false positive: patient thinks he has the disease when he doesn’t.
- Type II Error false negative: patient is told he is disease - free when in fact he has the disease.
- Jury Decisions
- Type I: found guilty when the defendant is innocent. Put an innocent person in jail.
- Type II: not enough evidence to convict, but was guilty. A murderer goes free.
Type I and Type II errors
As usual, when we conduct a statistical test of significance, we make a statement whether we can accept or reject the null hypothesis at some confidence level (usually 0.05)
We may be right or wrong – we never know the true state of the world, only the information obtained in our sample
Type I and Type II errors
So why not just set significance level at some very high level then? Why not only accept at the 0.001 level?
Setting a cutoff is actually a tradeoff between Type I vs. Type II statistical errors
If a researcher claims support for the research hypothesis with a significant result when, in fact, variations in results are caused by random variables alone, then a Type I error is said to have occurred.
Through poor design or faulty sampling, researchers may fail to achieve significance, even though the effect they were attempting to demonstrate actually does exist. In this case it would be said that they had made a Type II error.
Type I and Type II errors
Probabilities of Type I and Type II errors
-
- This represents the probability that if is true then we will reject
-
- We cannot calculate . Saying is false does not tell us what the parameter is
Decreasing results in an increase of
Reduce for all alternatives, by increasing
The only way to decrease both is to increase the sample size
Example: thinking about errors
The study found patients who took a certain drug to help with diabetes management have an increased risk of heart attack.
What kind of error if their findings were due to chance?
is true but they rejected .
- Type I error
Patients would be deprived of the diabetes drug’s benefits when there is no increased risk of heart attack.
Why shouldn’t we try to minimize Type I errors at all costs? What are some scenarios where a Type II error is actually more serious?
Power of a test
What we really want to do is to detect a false null hypothesis.
When is false and we reject it, we have done the right thing.
A test’s ability to detect a false null hypothesis is called the power of the test.
Power = 1 –
If a study fails to reject , either:
- was true. No error was made.
- is false. Type II error was made.
- Jury trial, power: ability of criminal justice system to convict people who are guilty—a good thing!
Example: errors and power
The meta study resulted in a larger study of 47 different trials.
How could this larger sample size help?
If the drug really did increase the chance of heart attack, doctors needed to know.
Missing this side effect would be a Type II error.
Increasing the sample size increases the power of the analysis, increasing the chance of detecting the danger if there is one.
Effect size
For same sample size, larger effect size results in higher power
A small effect size is difficult to detect, high probability of Type II error, lower power
Power depends on effect size and standard deviation.
The effect size depends on “How big a difference would matter?”
- In detecting the “human energy field” would a 53% or a 75% success rate be remarkable?
Effect size
When designing an experiment, need to know what effect size would be meaningful
- Important to specify this before conducting your study/experiment
Also useful to have an expectation about how variable your data are likely to be
With those estimates, and a little algebra, you can get an estimate of your required
To know how variable the data may be, you may need to run a “pilot” study or base calculations on previous similar studies.
If you fail to reject hypothesis, then consider whether test had sufficient power.
Example: sample size, errors, and power
The diabetes drug manufacturer looked at the study and rebutted that the sample size was too small.
Why would this smaller study have been less likely to detect a difference in risks?
- Small studies have more sampling variability.
- Small studies have less power.
- Hard to discern whether the difference is due to chance: Higher , since is fixed by the FDA.
- Large studies can reduce the risk of both errors.
- Larger studies are better but very expensive.
Ethics

“…let me put it this way. I think that many or most researchers think of statistical tests as a kind of annoying paperwork, a set of forms they need to fill out in order to get their work published. That’s an impression I’ve had of researchers for a long time: they feel they already know the truth–they conducted the damn experiment already!–so then they find whatever p-values are necessary to satisfy the reviewers.” - Andrew Gelman - Statistics Professor at Columbia